
Como empezar a analizar datos con Python usando Google Colab
Este es la tercer entrega de una serie de notas relacionadas a la puesta en marcha de experimentos en línea. En este caso trataremos un tema más general que podría interesarle a personas que tengan otro objetivo, pero que sin dudas puede ser una gran herramienta para cualquier persona que haga ciencia experimental.
Pueden ver la primera entrega acerca de como crear un experimento entrando a este link
Y la segunda acerca de como subirlo a la web gratuitamente.
Pueden seguir el tutorial con este cuaderno que contiene todo lo que se explicó, entrando al enlace y presionando en el botón “open in Colab”

En esta oportunidad quiero hablarles de Google Colaboratory (de aquí en más, simplememente “Colab”) una plataforma de uso gratuito que nos permite programar, ejecutar y analizar datos utilizando el lenguaje de programación Python.
Primero que nada: ¿Por qué explicás como hacer experimentos utilizando JavaScript si después vas a utilizar ooootro lenguaje más para analizar los datos? Si bien es cierto que se pueden usar herramientas en lenguaje Python (aunque de manera indirecta) para crear el experimento online, como ya expliqué en la primer entrega, las principales razones de mi elección se deben a que JavaScript es un lenguaje pensado para la web y por lo tanto es fácil encontrar maneras tanto de interactuar con los navegadores (donde se ejecutará nuestra tarea experimental) como con los servidores donde lo vamos a subir (el detrás de escena o backend). Si tu experimento lo realizaste con otro lenguaje (o sin programar), este tutorial igual te puede llegar a ser útil para analizar los datos.
Por otro lado me parece importante entender a cada lenguaje de programación como una herramienta que puede o no ser conveniente en función de cada objetivo particular. En este caso Python es uno de los más utilizados para análisis de datos, es de código abierto (gratuito) y posee una cantidad de librerías y una comunidad tan grandes que hace que sea una excelente opción para ese fin.
Volviendo a Colab, wikipedia nos dice:
Colaboratory (también conocido como Colab) es un entorno de notebook Jupyter gratuito que se ejecuta en la nube y almacena sus notebooks (cuadernos) en Google Drive. Colab fue originalmente un proyecto interno de Google; Se hizo un intento de abrir todo el código como fuente abierta y trabajar más directamente en sentido ascendente, lo que llevó al desarrollo de la extensión de Google Chrome "Open in Colab", pero esto finalmente terminó y el desarrollo de Colab continuó internamente.
Esto quiere decir que tendremos acceso a un Jupyter notebook (o cuaderno de Jupyter), una plataforma interactiva que funciona en nuestro navegador y está en la nube, donde podremos escribir código en Python, agregar texto con markdowns, mostrar imágenes, gráficos y mucho más ¡Todo en un solo lugar y de manera gratuita!
¿Cómo empiezo?
0. Creando una cuenta en Google
Si no contás con una cuenta una cuenta en Google (si tenés un mail en gmail, ya la ténés) es necesario que crees una. Podés hacerlo de manera sencilla siguiendo estos pasos. Esta cuenta te dará acceso a todos los servicios que ofrece Google de forma gratuita y, en particular, a los que nosotros nos interesan en este tutorial: El servicio de alojamiento de archivos en la nube Google Drive y por supuesto a Colab ;).
1. Conociendo la plataforma y haciendo la puesta a punto
Ingresando a la web de Google Colab nos encontraremos automáticamente con nuestro primer Notebook, que debería verse más o menos así:

Si estamos acostumbrados a usar otros servicios de Google como por ejemplo el procesador de texto Documentos de Google (Google Docs), la interfaz nos resultará algo familiar: Tenemos los menués (algunos clásicos como archivo o editar y otros nuevos como Entorno de ejecución) justo debajo del título y a la derecha el botón compartir tal cual como si fuera un documento de texto que estuvieramos compartiendo en la plataforma Google Drive. Las diferencias comienzan en que el cuerpo de nuestro documento ya no es un procesador de texto estándar sino que es un notebook interactivo en cual tenemos celdas. Estas divisiones pueden ser de dos tipos y las podemos crear con el correspondiente botón que se encuentra justo debajo del menú:
- Texto: Como su nombre lo indica, nos permitirá escribir texto plano y también utilizar el lenguaje de marcado Markdowns para darle formato. Por ejemplo podemos cambiarle el tamaño (anteponiendo #) o utilizar negrita (encerrado las palabras con **). Pueden ver ejemplos de uso ingresando a la siguiente entrada de wikipedia en español o a la guía de Google en inglés
- Código: Acá está lo interesante. Dentro de estas celdas podremos escribir todas las líneas que deseemos utilizando el lenguaje Python y, habiéndolas importado previamente, utilizando cualquier librería disponible. Para ejecutar cada celda podremos ir al botón con el símbolo ▶️ que aparece en la esquina superior izquierda o con el atajo Ctrl (o cmd) + Enter.
Cuando estén en la pestaña de Colab, en la esquina superior derecha verán un botón que dice
Conectar(oReconectar). Si clickean, les va a aparecer un menú como el de la siguiente imagen
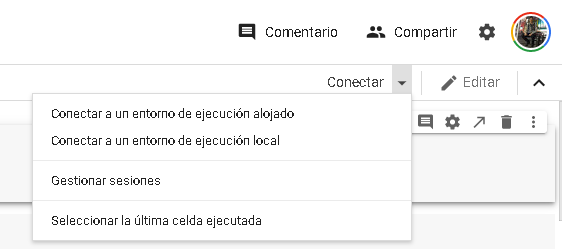
Presionando
Conectar a un entorno de ejecución alojadopodrán correr el notebook usando los recursos de Google cloud (es decir, de una computadora de Google), lo cual es mucho más rápido que usar la nuestra. Si quisieran usar sus propios recursos, deberán seleccionarConectar a un entorno de ejecución local(no lo recomiendo). De cualquier modo, lo que me interesa remarcar acá es que si en algún momento el notebook no está funcionando correctamente puede ser que se deba a que están desconectados y deberán presionar ese botón (esto puede pasar si no hacemos nada por cierto tiempo), normalmente no debemos preocuparnos por esto porque al correr nuestra primera celda de código se conectará automáticamente. Para una explicación más detallada sobre como usar diferentes entornos de ejecución entren acá.Finalmente, en el mismo menú verán un ícono de engranaje que les permitirá configurar varias cosas como el tema (claro u oscuro), tamaño de fuente, entre otras. Si quieren divertirse un rato pueden ir a “varios” y marcar modo gatito para ver lo que pasa (spoiler: no afecta en nada al análisis de datos).
2. Importando las librerias
Como en los tutoriales pasados donde trabajamos con JavaScript existía un modo de llamar nuevas funcionalidades, en Python eso se hace con la palabra reservada import seguida del nombre de la librería que queremos usar.
Para realizar análisis de datos utlizaremos cuatro librerías muy populares en Python: NumPy, la cual nos otorgará super poderes matemáticos, Pandas para trabajar con Data Frames (un tipo de tabla, similar a una hoja de cálculo de Excel), Matplotlib para generar visualizaciones y SciPy para análisis estadísticos y otros análisis numéricos (pongo los links a wikipedia porque está en español, pero recomiendo fuertemente que lean la documentación de sus páginas oficiales, las mismas se encuentran fácilmente poniendo su nombre + Python en el buscador).
Para comenzar crearemos una celda de código para importar las librerías:
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from scipy import statsEsto nos permite acceder a un nuevo abanico de funciones muy útiles para el trabajo con datos.
¿Qué es lo primero que necesitamos para poder realizar nuestro análisis de datos? ¡Si, los datos! Hacia allí vamos.
1. Carga
Si no estamos acostumbrados a usar un lenguaje de programación para analizar los datos de nuestros experimentos, lo más común es que hayamos utilizado algún software para tal fin (por ejemplo Microsoft® Excel®), si bien este tipo de programas tienen la ventaja de su facilidad de uso por medio de una interfaz gráfica y una gran capacidad para realizar poderosos análisis de datos, limitan la flexibilidad a la hora de hacerlos. Podría darse el caso de querer utilizar alguna funcionalidad aun no implementada o un nuevo modo de realizarla alguna de las ya existentes, además de tres problemas graves: menor control sobre la forma en que se lleva a cabo el análisis, el hecho de ser software propietario (no es gratis y no sabemos como fue desarrollado) y una menor posibilidad de automatización de tareas (tanto en el análisis como lo que querramos hacer antes y después del mismo).
Para iniciar la carga de datos tenemos varias opciones que podemos encontrar yendo al ícono con forma de carpeta de la barra lateral.
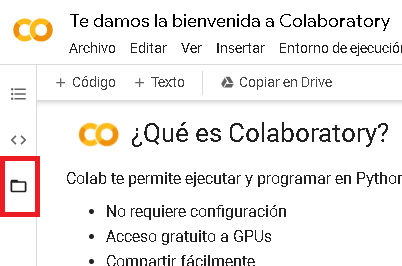
Al desplegarlo nos encontramos con tres botones:
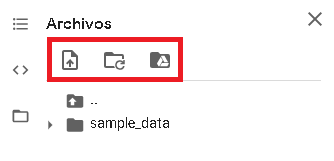
- Subir almacenamiento de sesión: Esta primera opción nos permite subir archivos desde nuestra computadora, pero solo por la sesión en la que estamos trabajando. Es decir, que si cerramos la pestaña (técnicamenta cuando cerramos el entorno de ejecución) esos datos no quedarán guardados. Solo lo recomendaría para probar alguna cosa rápida, pero en general no es lo ideal.
- Actualizar: Si acabamos de hacer algún cambio como agregar o borrar arhivos y todavía no lo vemos reflejado en el gestor. Por ejemplo, la presencia de una nueva carpeta.
- Activar Drive: Esta opción generará una nueva celda de código con los comandos necesarios para cargar archivos previamente subidos a nuestro Google Drive:
from google.colab import drive
drive.mount('content/drive')Al ejecutarla nos aparecerá un vínculo a una página (o URL) donde se nos pedirá acceso a nuestro Drive, seleccionamos la cuenta con la que queremos ingresar y presionaremos aceptar. A continuación nos aparecerá una pantalla como esta:

Simplemente copiamos ese código, volvemos a Colab, lo pegamos en la casilla que se encuentra debajo de Enter your authorization code (ingrese su código de autorización). Les aparecerá Mounted at /content/drive y ya tendrán acceso a los archivos que allí tengan guardados.
Para acceder específicamente al archivo con el que querramos trabajar debemos colocar su ruta de accceso completa. En este caso, aunque no sea el ejemplo más sencillo, usaremos datos reales obtenidos a partir de un experimento online, en un archivo .csv tal cual como nos lo provee la plataforma cognition.run (como aprendimos en el tutorial anterior). Utilizaremos el archivo go-no-go.csv que pueden descargar en este enlace (si no están muy familiarizados con git pueden bajar el .zip desde acá, no se olviden de descompromirlo porque lo necesitamos en formato .csv). Si lo guardamos en Google Drive en una carpeta llamada datos_de_mi_experimento podremos acceder a él a través de la siguiente ruta: /content/drive/MyDrive/datos_de_mi_experimento/go-no-go.csv

En el experimento las persona tenían que presionar una tecla si aparecía el círculo azul y otra si aparecía el naranja. Los tiempos de reacción (o reaction times) se registraron en cada caso.
Lo que haremos a continuación es cargarlo como un Data Frame, un tipo de tabla similar a lo que tendríamos en una hoja de cálculo, ejecutando una celda con el siguiente contenido:
df = pd.read_csv("/content/drive/My Drive/datos_de_mi_experimento/primer-experimento-36.csv")Ahora que definimos la variable df como un dataframe con nuestros datos, podemos averiguar sus dimensiones:
# Esta celda nos devuelve: (filas,columnas)
df.size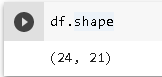
y ver que contiene escribiendo esta otra celda:
df.head()Al ejecutarla obtendremos algo similar a esto:
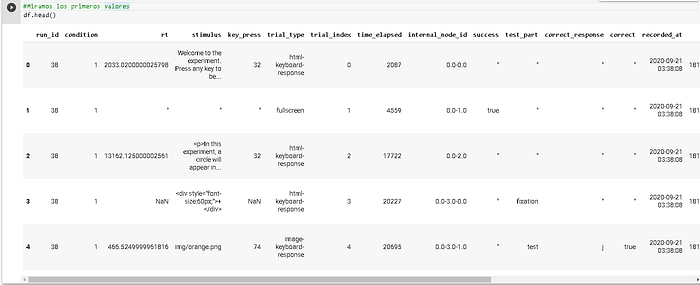
Vemos las primeras cinco filas de nuestros dataframe (el índice del primer elemento es 0) con cada columna reperesentando a una variable. Por ejemplo run_id (la corrida de nuestro experimento que descargamos de cognition), condition (la condición que se le presentó al participante, en este caso había solo una) rt (tiempo de respuesta), stimulus (estímulo presentado), entre otras. Por otro lado, cada fila es un dato, como en el caso de la columna rt, donde cada fila corresponde al tiempo de reacción del participante en ese ensayo.
Normalmente cuando tomamos datos, los organizamos en alguna estructura con formato de tabla. Ya sea porque medimos algo que varía en el tiempo (serie temporal) o en el espacio, la mayoría de las veces tenemos una serie de variables que varían en función de nuestras condiciones. Este tipo de datos son los que suelen cargarse en programas como Excel para luego llevar a cabo los correspondientes análisis. En este caso lo haremos a través de código cargando los datos en un Data Frame, que no es más que un tipo de estructura similar a una tabla.
2. Exploración
Es común que cuando comencemos a revistar nuestros datos querramos tener algunas estadísticas generales para saber, a grandes rasgos, qué características tienen. Una manera sencilla de realizar este análisis exploratorio es mediante el método describe, el cual nos permitirá, mediante una sola línea de código acceder al número de muestras, el valor medio, la desviación estándar, el valor mínimo, máximo, la mediana y los valores correspondientes a los percentiles 25% y 75%, de nuestros datos.

¿Pero por qué hay solo cinco columnas si mi dataframe tenía 21?
La respuesta es que el método describe solo actúa sobre las columnas que tengan elementos de tipo numérico (esto no es cierto en todos los casos, para ver más detalles les recomiendo leer la documentación).
Así que podemos usar el método dtypes sobre cada columna de nuestro dataframe a las cuales acccedemos como df[‘NombreDeLaColumna’]

int y float son tipos numéricos (entero y punto flotante respectivamente).
3. Limpiando y graficando
Ahora que ya tenemos nuestro dataframe somos libres para hacer cualquier tipo de análisis que se nos ocurra, pero como ya vimos, hay que ser cuidadosos con el tipo de datos que manipulemos.
Por ejemplo para la tarea de tiempo de reacción que subimos a internet en el tutorial anterior, y al cual pertenecen los datos que estamos utilizando, podríamos ver si hay diferencias en los tiempos de reacción para los círculos de un color y del otro.
Para eso, podríamos filtrar los tiempos de respuesta basándonos en la columna stimulus para diferenciar los que correspondan a círculos presentados de color azul (blue.png) y de color naranja (orange.png) :

Lo que hicimos fue filtrar por columnas que contengan el texto correspondiente (organge o blue)y luego quedarnos con los rt de esas filas. Ahora tenemos que asegurarnos del tipo de datos que contienen.

Lo que sucede es que la columna tiene datos heterogéneos entonces el tipo de dato que reconoce pandas es Object (Pueden leer más al respecto acá), por lo cual lo transformaremos a datos numéricos y además nos desharemos de los NaN (elementos que no son un número o Not a Number):

De este modo estamos listos para hacer un gráfico básico, en este caso utilizaré un box plot, pero la amplitud de posbiliades que permite matplotlib es enorme. Si quieren ver algunos ejemplos pueden entrar acá.

Pueden parecer muchas líneas de código pero la mayoría están para agregar estilo y colores. El resultado se verá así:
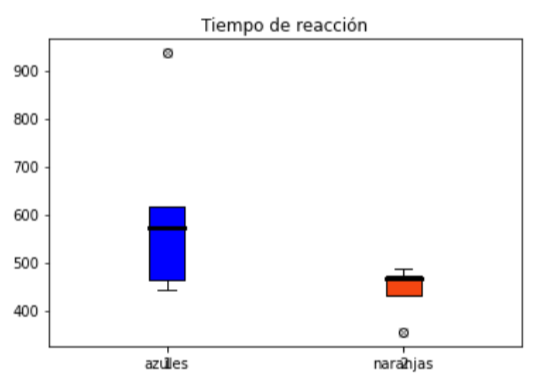
Un gráfico super sencillo solo para mostrar un ejemplo, pero les invito a probar y experimentar con muchos otros ejemplos.
3. Análisis estadístico básico
Finalmente también me gustaría mostrar que pueden hacerse análisis estadísticos de lo que se ocurra. En este caso utilizaremos la librería SciPy para hacer un t-test, pero acá pueden ver muchos otros ejempos.
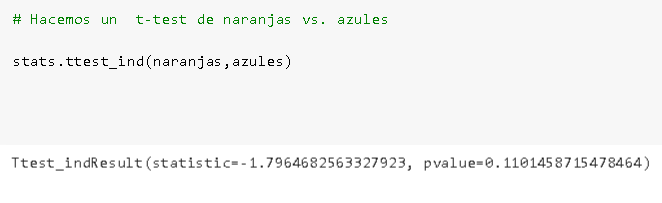
Tan sencillo como una línea de código!
Para ver el cuaderno con todo lo explicado podés entrar acá y presionar en el botón que dice “Open in Colab”.
Opciones un poco más avanzadas
- Colab permite correr código como si se tratara de una terminal utilizando el símbolo ! dentro de una celda de código. De este modo es posible crear directorios con mkdir, mover archivos o incluso instalar cualquier dependencia. Por ejemplo si necesitamos alguna librería que no se encuentra por defecto en el entorno de desarrollo de google colab podemos hacerlo de este modo:
!pip install LoQueQuerramosInstalar- Los cuadernos de Jupyter Notebook como de los que disponemos en Colab utilizan IPython, lo que nos da acceso a comandos mágicos que se pueden utilizar mediante el prefijo %. Por ejemplo podríamos embeber un video directamente en nuestro cuaderno del siguiente modo:
from IPython.display import HTML#Podemos agregar cualquier utilizando HTMLHTML('<iframe width="560" height="315" src="https://www.youtube.com/embed/lTTZ8PkQ_Pk" frameborder="0" allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>')
- Podemos ocultar celdas, donde solo se vea un título y al al hacer doble click se despliegue su contenido. La forma de hacerlo es agregando la siguiente línea en la parte superior de la celda que queremos modificar:
# @title TextoDeMiTítuloEste tipo de funcionalidades muestran la potencia de esta plataforma.
Conclusiones
El objetivo de este tutorial es lograr que las personas empiecen a poner sus pies en el lago del análisis de datos con Python y para nada intenta ser exhaustivo. Cada una de las herramientas presentadas tiene muchas funcionalidades y lo que más me interesa es que esto genere curiosidad e interés en aprender más.
En mi opinión el uso de lenguajes de programación para el análisis de datos, en lugar de un software cerrado, es algo que va a seguir creciendo en la comunidad científica, ya que cada vez la cantidad de datos que se obtienen es mayor, los análisis más sofisticados y las herramientas basadas en código cada vez más fáciles de utilizar, baratas (o gratis!) y accesibles por la comunidad que en el caso de Python es buenísima compartiendo.
Referencias
Como siempre los recursos más completos son las documentaciones oficiales de las tecnologías, pero les dejo además algunos cursos que me parecen de calidad y además son gratuitos.
En español:
En inglés:
- Excelente contenido de la gente de Software Carpentry. Muy útil para empezar con Python y en particular para análisis de datos.
- Los cursos de Kaggle sobre Python, análisis de datos y Machine Learning.
